Here’s my shot at comparing the two currently most popular frameworks for large-scale agile, SAFe and LeSS. Looking beneath the surface, how do they differ?
(updated 2022-05-24)
 – Agile, Scrum, xP, Kanban, Lean: the same elephant, different points of view
– Agile, Scrum, xP, Kanban, Lean: the same elephant, different points of view
-Ron Jeffries
Having looked at the R&D scene since 1999, I’ve worked with many organizations which have tried to adopt some form of multi-team agile with planning horizons beyond the next two weeks. I was also, back in 2001, one of the authors of the first framework that attempted to capture elements common to lightweight methods – as they were called before the second and more famous Snowbird meeting.
More recently, I’ve been stymied how many evangelists who teach scaling agile tend to ignore, or at least disregard, the existence of “the other frameworks”.
When asked to compare, most proponents mostly say that they don’t know much of ”the other ones”. Or, they simply refuse to do an analysis of the similarities and differences of the frameworks as the other ones are “something completely different” (although nowadays exceptions of a reasonable quality do exist, such as this, this, this, this and that post/podcast).
In 2018, I had the chance to obtain both the SAFe Program Consultant as well as the LeSS Practitioner certificates. After having conducted some two-digit number trainings of Leading SAFe and the SAFe Product Owner/Product Manager courses, as well as putting together a non-framework -based product owner training of my own I’ve started to get an eerie feeling.
SAFe and LeSS actually are quite close to each other. At least in terms of essence, if not in terms of emphasis, presentation, and packaging.
To me it seems the stances are a bit like in the case of Scrum versus Kanban in the 2000’s – a silly thing already then – being brought back to the present. And funnily enough, the discussion of Kanban vs. Scrum is still ongoing, though it’s mostly carried on by tool vendors, PMI folks and those practitioners whose understanding of both Scrum and Kanban is a bit off.
Perhaps, if there’s a wall between the frameworks, it has risen as a side-effect of the commercial aspects, misunderstandings, and a tad of ethical dissonance?
In any case, the prevailing dichotomy does little to serve the industry. And based on what history teaches us, it is not going to be dismantled any time soon – unless we who are less vested in a particular framework take action.
A comparison of SAFe and LeSS
So, enter my version of the comparison!
Yes, there are other comparisons out there, better, worse, list-like and those which are a nice read but remain on a superficial level (another recent example of that here). But simply saying for example that “LeSS has no portfolio management” does not quite hit the mark. There are deeper aspects and differences – as well as essential similarities – which deserve attention.
Before delving deeper, let’s first look at the ‘why’ behind both of the frameworks’ existence.
As put forward by Scaled Agile Inc.’s president (2019) Chris James, SAFe’s approach is to collect all “proven good practices and patterns” and from there you can “tailor down according to your needs”.
In turn, according to the co-creator of LeSS Bas Vodde, LeSS attempts to offer “a barely sufficient” methodology and suggests to build up your methodology, as, quoting Barry Boehm, “tailoring down does not work in practice”.
In the sections below I’ve compared and contrasted some aspects in SAFe and LeSS. I have attempted to focus on the most interesting ones, as a run-through of all the elements in SAFe and reciting that ”LeSS does not contain such a thing but of course you could add it” would hardly be meaningful.
In particular, I’ve discussed:
- Principles
- Organization design
- Team and organization size
- Adoption steps
- Cadence
- Requirement meta-model
- Content management
- Cross-team coordination, and
- Portfolio management
If you’re curious about a particular aspect I have not addressed, feel free to reach out and I’ll try to add, or at least share some comment about it.
Principles
SAFe: Take an economic view; Apply systems thinking; Assume variability, preserve options; Build incrementally with fast, integrated learning cycles; Base milestones on objective evaluation of working systems; Visualize and limit WiP, reduce batch sizes and manage queue lengths; Apply cadence, synchronize with cross-domain planning; Unlock the intrinsic motivation of knowledge workers; Decentralize decision-making, Organize around value
LeSS: LeSS is Scrum; Empirical process control; Transparency; More with less; Whole-product focus; Customer-centric; Continuous improvement towards perfection; Systems thinking; Lean thinking; Queuing theory
SAFe’s principles are largely based on Don Reinertsen’s book on product development flow. Still, the principles of both of the frameworks, with the exception of “LeSS is Scrum” and “More with less” seem – at least to me – essentially the same, with SAFe’s version being more verbose.
The main difference seems to be that two of LeSS’s principles – whole-product focus and customer-centricity – are explicitly concerned with organizing around customer value. SAFe’s principles nowadays contain that as well, but before SAFe version 4, it could not have been discerned by just looking at the “headlines”.
Organization design
SAFe: Mapping the value streams and identifying Agile Release Trains
LeSS: Identifying product owners and restructuring the organization into feature teams.
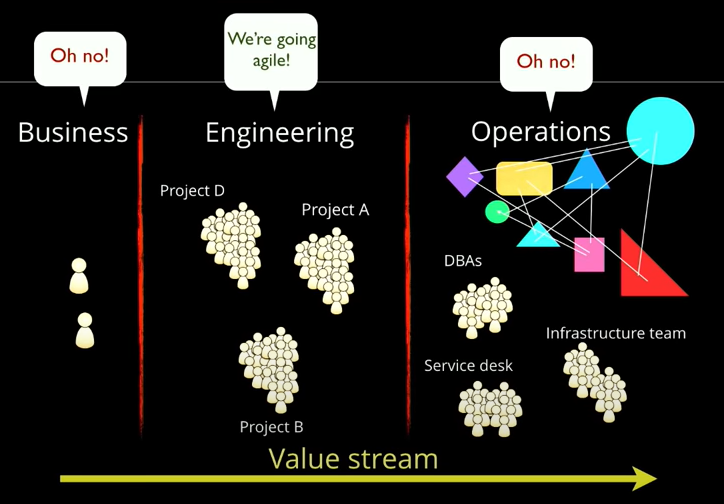
SAFe implies organizing around customer value delivery. However, SAFe remains somewhat implicit about this. For example, there’s no mention of feature teams in the big picture, and one can find material which describes trains organized around subsystems as “architecturally robust”, adding that in such a case “there will be many dependencies and lots of Work-in-Progress”.
Interestingly enough, rather many SAFe adoptions I’ve seen have ’agile release trains’ organized around subsystems and are incapable of releasing to production.
I had a chat about this with a Certified SAFe Program Coach Trainer who at the time was employed at Scaled Agile Inc. Like I had suspected, the idea behind this rather ambivalent stance is to get a foot into the door in order to start helping organizations at the level where they currently are.
While SAFe’s material on value streams is still at points slightly superficial, these concepts from lean were first presented in the context of software development in books by Mary and Tom Poppendieck and you can read more about them there.
LeSS emphasises the importance of changing the structure of the organization into feature teams and eliminating all outside-of-the-team roles except the product owner. As an example, DevOps is considered to be to be a harmful misnomer, as the “original idea was to eliminate ops”. In fact, Bas Vodde rather refers to LeSS as ‘an organization design framework’ than a ‘scaling framework’. While in large organizations the change in organizational structure can happen gradually, organizations with 50 people or less can and should be flipped in a single go.
As for LeSS adoptions … I have yet to see them. And yes, it is quite easily imagined that a LeSS consultant, after rubbing the total structural changes needed, the abolishment of titles, removal of career paths and dismantling the reward systems in the management’s face, might get shown the door.
LeSS does, however, has a concept which would be useful in improving your typical SAFe adoption: Undone Work and the Undone Department.
Team and organization size
SAFe: Teams are 5-11 people, and an agile release train 5-12 teams + the other needed roles (50-125 people)
LeSS: Teams are 5-9 people, and the dev org 3-8 teams + product owner (16-73 people)
For those development organizations which are larger than those stated above, SAFe employs multiple trains for the same solution. In similar fashion, LeSS employs multiple requirement areas (called “LeSS Huge”). In the large solution case, SAFe’s solution management corresponds to the LeSS product owner, whereas program level product managers match LeSS’s area product owners.
Looking for differences, while the team size in both of the frameworks is based on Scrum, the overall numbers in LeSS are smaller. Likewise, the split into multiple requirement areas and area product owners is recommended in the range where according to SAFe, a single train would still be enough.
Otherwise, the approaches match each other quite closely.
Adoption steps
SAFe: a) Train lean-agile change agents; train executives, managers & leaders b) Identify value streams and ARTs c) Prepare and launch ARTs d) Coach and launch more ARTs e) Extend to the portfolio
LeSS: a) Educate everyone involved in the transformation b) Define the product, define done, have appropriately structured teams c) Only the product owner gives work to the teams; keep project managers away from the teams d) Repeat until entire organization transformed
As you can see, both of the frameworks start from training everyone and both emphasize the importance of training the top management. SAFe talks about value stream identification, whereas this is essentially the same thing as defining the whole product in LeSS. Then, the notion of forming ARTs (SAFe) and restructuring teams (LeSS) are very close to each other, and both start with a part of an organization and repeat until done.
The difference is that while LeSS suggests transforming a part of the organization at a time (end thus, creating implicit portfolio management for that area), SAFe “extends to the portfolio” only after launching all the trains.
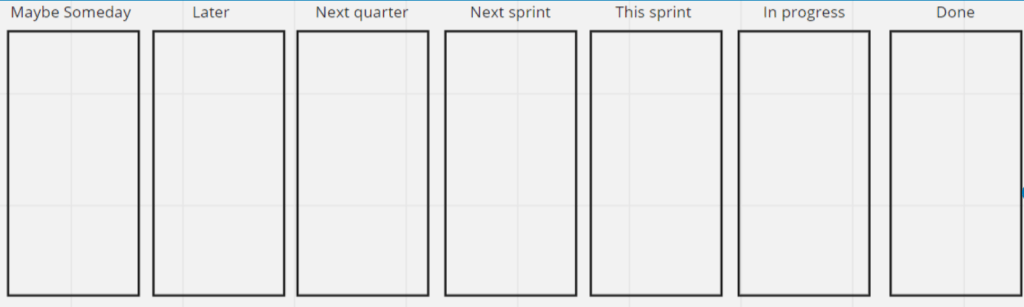
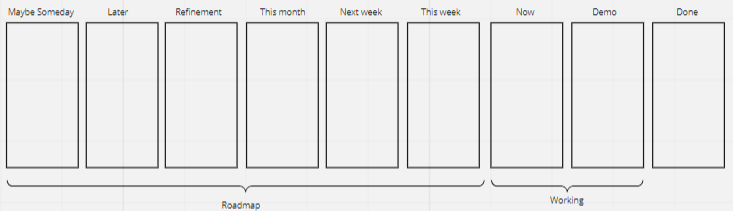
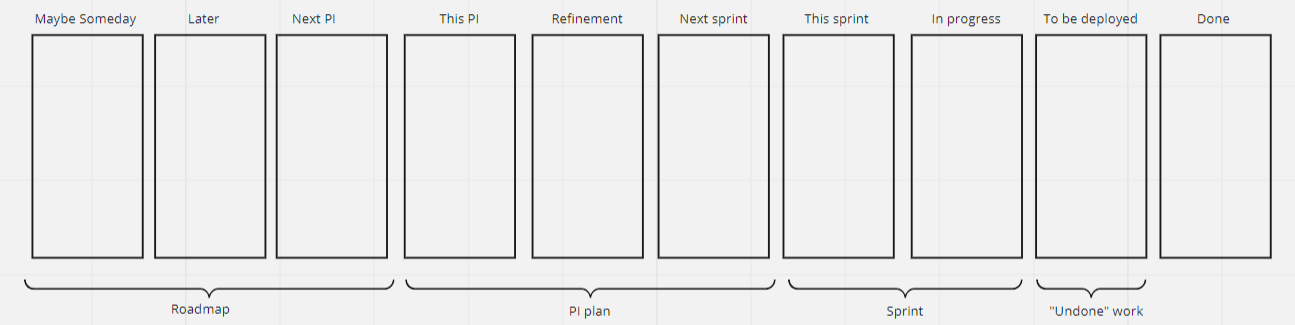
Cadence
SAFe: Synchronized 2 week sprints and 8-12 week program increments
LeSS: Synchronized sprints; does not dictate length (but 2 weeks is often implied). Emphasizes that “the sprint is for the product”, not the organization
In SAFe, teams can also “operate in kanban”, but “adhering to SAFe specific rules” where teams plan, demo and do retros together. This does in practice make it quite similar to operating in sprints.
At least when first starting with LeSS, you can do “release planning” in a very similar fashion to SAFe’s program increments. And what’s to say it should be dropped later on?
To quote my LeSS certification course teacher Ran Nyman: “Sure you can add a construct similar to SAFe’s program increment to your methodology – but only do so if you’re persistently in great pain without it”.
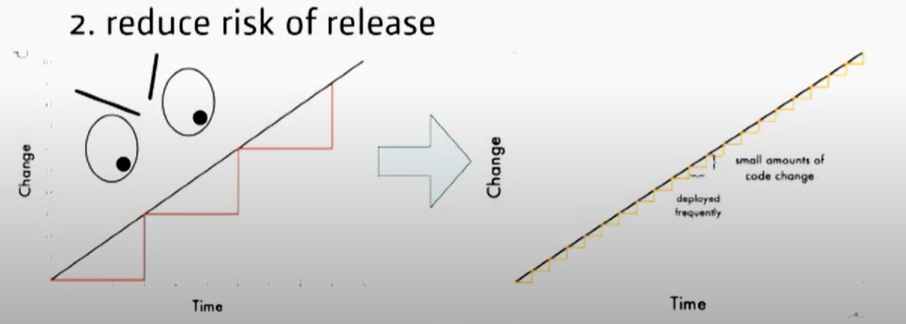
As the goal in both frameworks is to be able to ship the working and tested solution (roughly) every two weeks, their take on cadence is very much the same. At least in theory, for in practice the concept of PI planning tends to drive batch sizes up. Compared with sticking to plain two-week Sprints, that is.
Requirement meta-model
SAFe: Epics (do not fit into a Program Increment), Features (should fit into a program increment but not into a 2-week iteration) and Stories (should fit into a two-week iteration).
LeSS: No explicit requirements meta-model; try to use a flat list, and if you can’t, stop at three levels maximum
The notion of requirement meta-models dates to somewhere around 2005 in the work of a group of Swedish researchers (see publications 57-59). While around 2010 other models were also introduced, SAFe’s three-level Epic-Feature-Story model, based on a white paper from Nokia written by Juha-Markus Aalto, has emerged as the most popular one.
LeSS advises to avoid backlog structures with many levels of splitting and recommends that one should definitely “stop at three levels maximum”. This is because having many nested levels increases complexity, as well as tends to result in diverting from customer-centric requirements.
While SAFe and LeSS differ slightly, I think they both are a bit off here – at least when it comes to tree-like splitting.
I’m inclined to think that most of the challenges in dealing with nested levels of requirements actually have to do with inadequate tooling, which in turn stems from physical boards, index cards, and considering the backlog as a flat list.
My two cents is that if you go for tree-like splitting, you should allow for infinite levels as well as abolish explicit taxonomies. Otherwise, you end up driving up batch size in subtle ways which in turn lead to very tangible problems.
Content management
SAFe: Product manager owns the program backlog and team product owners own the sprint backlogs. In addition, there are program-level PI objectives, summed up from the team PI objectives which are in PI planning scored by the Business
LeSS: Product owner owns the product backlog, the team owns the sprint backlog. Optional Sprint goal, devised by the team and the product owner
I’ve divided the discussion into two sections: backlogs and content ownership and goal setting.
Backlogs and content ownership
Despite SAFe’s distinct portfolio level, the ultimate decision on what goes into the program increments resides with the Product Manager role. This holds true for LeSS’s product owner as well.
Overall, SAFe’s product manager and LeSS’s product owner roles are quite similar. While SAFe explicates further content owner roles such as Business owners and Epic owners, I interpret this as a way of actually making the product owner more specific – and similar to the role as originally defined in Scrum. LeSS leaves such details out and talks about product ownership being a deeply collaborative activity with the stakeholders.
But the real differences come at the sprint level.
SAFe recommends that each team should have a product owner, and that at least most of the sprint level work items (stories) should be connected to parent work items (features). LeSS, in turn, advises against both of these things. The creators of of LeSS consider that having a product owner per team promotes local optimization.
In LeSS, Product and Sprint Backlogs are also intended as separate and independent artifacts. The teams should be able to choose their own way of keeping track of sprint-level work. They should also be trusted to understand and communicate about their progress without explicitly using a tool to tie sprint content to product backlog items.
Goal setting
In terms of goal setting, aside from the vision, SAFe has PI objectives and iteration goals, whereas LeSS has sprint goals.
The obvious difference here most likely stems from the differing cadences put forward by the frameworks. As a Program Increment contains several sprints by several teams, and each team has a set of their own PI objectives, summarizing those into program level PI objectives is only natural.
The collection of LeSS’s Sprint Goals (one for each team) are essentially the same, but for a shorter time period. Thus, summarizing is not needed.
But a less obvious, and to me a rather interesting aspect here is that SAFe has the construct of PO objectives in the first place. Also, there is a degree formality related to their use (compared to e.g. the rather vague definitions of sprint/iteration goals which have lingered around since the early 2000s).
Team level PI objectives are scored by the business people, and are then used to calculate the PI predictability measure at the end of a program increment.
Let’s take a moment to discuss this. The original intent in the manifesto for agile software development was to have the business and development work together daily. Also, user stories, as originally intended, did contain the expected benefits in terms that the business understands.
Now, in your typical real-life large-scale setting, the business people are hardly participating in development decision-making at all – at least before “the transformation”. They have too much important management stuff to do.
Also the use of stories at the team level has surprisingly often degenerated into something akin to “As the system, I want to have a button so that I can press it to print” silliness.
The PI objectives in SAFe seem to me like a tailor-made mechanism to pull the business into the discussion at least every quarter or so, without having to force them completely out of their comfort zone and join the discussion of these “agile stories” on a bi-weekly – or God forbid – daily basis. Interestingly enough, in the cases where I’ve seen PI objectives used by-the-book, they very much resemble product backlog items as they were originally intended.
Whether having – in addition to the backlog(s) – such a scoring wrapper in the long run is the safest (pun intended) route to take – as opposed to actually pursuing daily collaboration, spreading the knowledge about the proper use of a product backlog, collaborating with user stories and learning to do vertical splitting together with the teams, I’ll leave aside for now.
Having said that, the PI predictability metric is good in the sense that it’s harder to game than for example measuring velocities, function points, or some other silliness.
Cross-team coordination
SAFe: The Release Train Engineer role and Agile Release Train sync meetings
LeSS: The teams are responsible for cross-team coordination; in addition, you can have “town hall meetings”, “problem solving open space meetings”, “scrum of scrums” and whatever you need
According to SAFe, “agile release trains won’t steer themselves on autopilot” and the release train engineer role is there to facilitate cross-team coordination.
LeSS does not have an explicit coordinating role, because its creators considered that having such a role would unnecessarily take away responsibility from the teams.
Portfolio management
SAFe: Explicit strategic themes, portfolio canvas, rolling-wave funding of value streams, budgeting guard rails, a kanban for prioritizing and managing Epics, and the Epic owner role
LeSS: Portfolio management happens via backlog prioritization
Understanding LeSS’s stance on portfolio management would require a bit of explanation, but a piece about this is already out there.
Essentially, LeSS suggests that in the case of a correctly structured organization and a broad enough product definition, portfolio management is de facto reduced to backlog management. In the case of LeSS Huge, ‘portfolio management’ also includes shifting teams from one requirement area to another. And the demand for such shifts comes from… yes, backlog prioritization.
On the surface, SAFe portfolio management looks quite different from that in LeSS. Despite the added number of elements and artifacts, I find it essentially the same. For example, if value stream funding changes, surely the number of teams working in the trains – or the number of trains – are the variables which change as well.
Having said that, limiting the number of work-in-progress on the portfolio level is the most effective way to improve an organization’s performance – even without changing the structures and practices in the development organization.
To look at this from the perspective of offering an organization an easier path to transform its portfolio management, SAFe does, by describing a ready-made set of artifacts and roles offer better novice-level guidance here. Again, whether such a path is on the long run safer and faster is unknown to me.
What about the other scaling frameworks?
You might be wondering why I haven’t included other scaling frameworks to the comparison? First of all, SAFe and LeSS seem today to be the most popular, as well as best described.
To scratch the surface of the other approaches out there, Ken Schwaber’s Nexus is very close to LeSS with a bit more structure around how to do cross-team coordination. The so-called “Spotify model”, as originally described – I have no clue what Spotify’s doing today – was structure-wise also very close to LeSS. Likewise, Jeff Sutherland’s Scrum@Scale is quite close to LeSS – but actually has even less structure to it. On the surface it seems to simply recommend that everybody in the company should do Scrum.
Perhaps in the future I might take a deeper look into Nexus and Scrum@Scale.
The kettle and the pot
I’ll end with quotes from both frameworks’ proponents:
“SAFe is based on the Lean-Agile principles and the agile manifesto. […] It would be great if big companies who build important systems could start from scratch and start with a team of five, ten or fifteen and build it. But often they already have thousands of people in place and SAFe provides a bigger picture of how they could operate with a different mindset and what the principles, the practices and the roles could be.” (Chris James, COO of Scaled Agile Inc. @ Panel on Agile Scaling Frameworks And Their Ecosystem – Boon or Bane at #AgileIndia2017)
“LeSS is true to agile development and the origins of Scrum and is about creating the bare minimum and more ownership for the team. It is about moving away from heavy-weight processes and roles within organizations. Complex organizations are slow, and in LeSS you want to create a simple organization, which can better make the product(s).” (Bas Vodde, co-creator of LeSS, @ The Agile Standup Podcast)
Perhaps one of these resonates with your transformation efforts? Or perhaps not? Remember that you don’t have to – or perhaps even should not “choose” either!
As it happens, both frameworks have strong roots in Finland, from companies such as both of the Nokias, F-Secure, and Ericsson – among others.
And not-so-coincidentally, Nitor’s Transformation Engineers – myself, Maarit Laanti, Rami Sirkiä, Kirsi Mikkonen, Rauno Kosamo, Marko Setälä, Juha Itkonen, Antti Tevanlinna and Kati Laine – just to mention a few – have, since early 2000s, been involved in the work which has since resulted in both SAFe and LeSS.
So whether you pick one framework, the other, both – or wish to go your own way, we can help you transform your organization.





















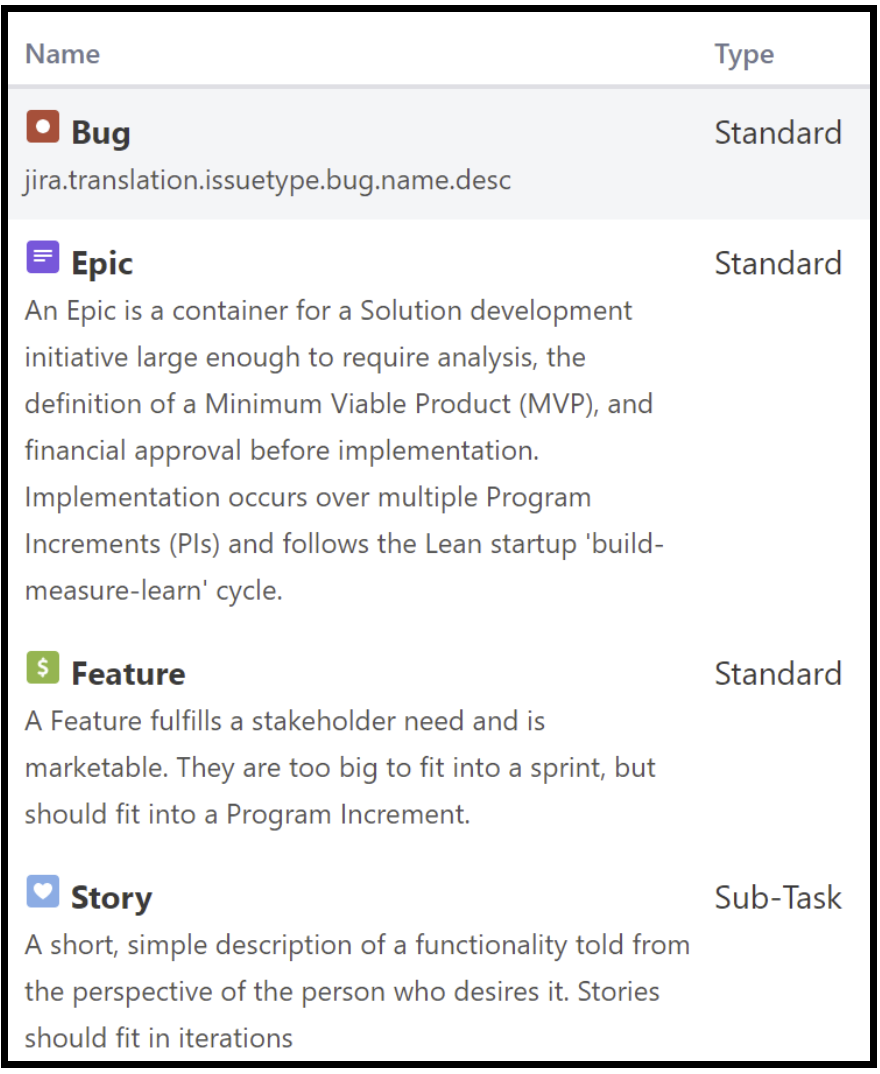
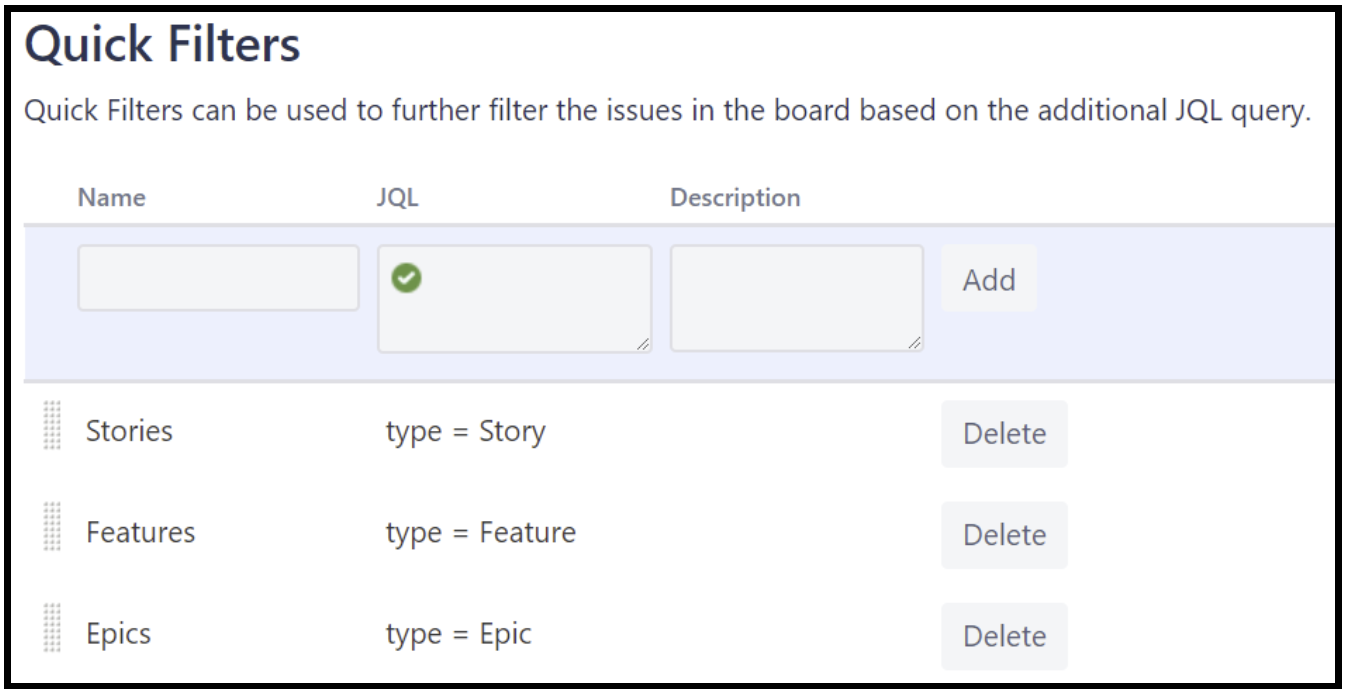






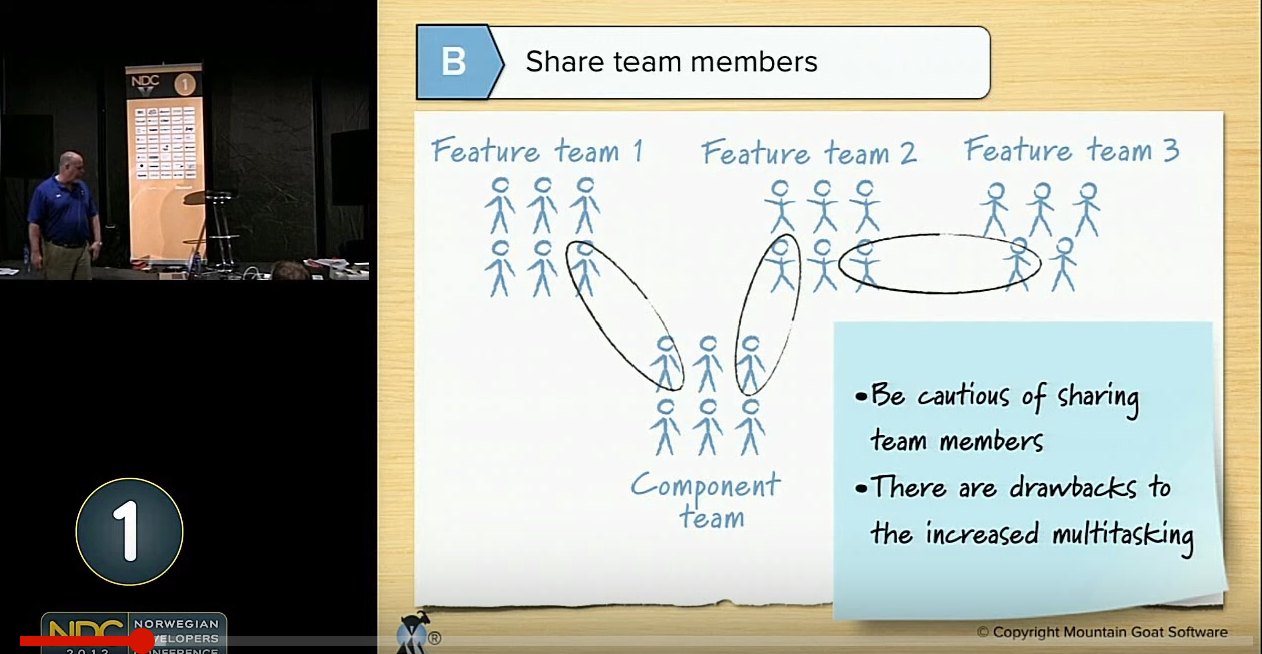
















 – Avoid a complex requirements meta-model (Larman & Vodde, 2010)
– Avoid a complex requirements meta-model (Larman & Vodde, 2010)

{kind=link}
{kind=link}