Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
Sane BDD (or doing BDD without Cucumber and regular expressions)
Lots of rubyists like cucumber. Or in the php world behat.
BDD seems like a very good idea on the face of it, especially for functional tests.
But I have always had a problem with how these frameworks rely on regular expressions to process their tests that are written in human readable text.
Jamie Zawinski famously said:
Some people, when confronted with a problem, think ‘I know,
I’ll use regular expressions.’ Now they have two problems.
…and I can wholeheartedly agree with that.
You want your test code to exercise your application, and not to worry too much about the robustness of your test code. And yet by relying on regular expressions you are using one of the brittlest parts of software engineering as the basis of your test code.
This seems mental.
So I was very pleased to see this blog post by Chris Zetter which describes an elegant way of providing the human readable tests of cucumber, but only using rspec to process them.
This is how I will do BDD from now on.
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
Queuing in Drupal vs Rails (with Delayed Job)
I have been doing quite a bit of coding in Drupal recently, although I consider myself more of a rubyist and Rails programmer.
Now none of this is a fair comparison, Drupal and Rails are not directly comparable (Drupal is a customisable CMS, Rails is a framework), yadda, yadda… but after a few days of coding Drupal queues, it is an interesting comparison how the interface differs for managing a common software engineering problem: queuing.
How to queue in Drupal
1) Define your queue using hook_cron_queue_info
function my_module_cron_queue_info() {
$queues['my_queue'] = array(
'worker callback' => 'my_module_queue_runner',
'time' => 5,
);
Which includes a ‘worker_callback’ which is the function that is run by the queue.
2) Add items to the queue
$item = array('some' => 'params', 'for' => 'my_module_queue_runner');
$queue = DrupalQueue::get('my_queue');
$queue->createItem($item);
3) Create the my_module_queue_runner function
function my_module_queue_runner($item) {// Do stuff asynchronously based on the contents of $item
}
4) Run the queue with
drush_queue_run('my_queue');
How to queue in Rails with delayed job
1) Assuming you already have an object and a method that you want to execute, just asynchronously
object.delay.method
2) Run the queue with
rake jobs:work
And that’s it…
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
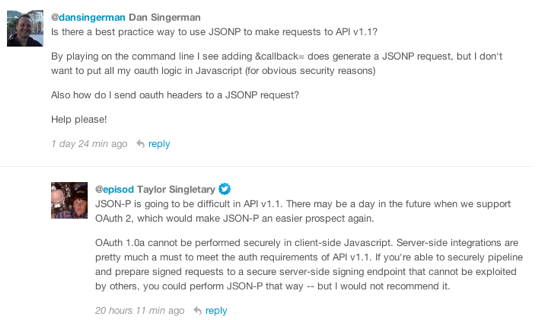
Twitter effectively killing JSONP too
Lost in all the recent Twitter announcements about changing rate limits, killing ATOM, RSS and XML, and ‘sunsetting’ Anywhere, is the fact that by only allowing OAUTH authenticated requests to version 1.1 of the REST API (which come March 6th will be the only REST API available), they are also effectively killing JSONP access.
What does this mean to developers?
Well, in practice it means all Twitter API requests will now need to be server to server. The scaling advantages of having a browser be able to make requests directly to the Twitter API will be completely removed.
Also, access to the streaming API is not available to browsers (this rather neat library using flash - used to work, until Twitter removed the crossdomain.xml file for stream.twitter.com to effectively block the use of clients like that.)
Whether this is a deliberate policy of Twitter’s to ensure all communication is server-to-server is not completely clear - from the tone of @episod’s reply to my question my reading is that this is a side effect of changes they are making, not necessarily deliberate.
However, it may well reduce the number of API requests that can be made (as they are removing all browser requests) which may result in a large cost saving for them, so in light of that who can blame them?
Unfortunately this rather FUBARs my current side project I’ve been working on: www.twitcrowd.com , so I’m going to put a hold on development of that, unless the situation changes again to make it feasible.
What’s the lesson here?
If you build on top of someone else’s ecosystem, they can change the rules as they see fit, and there’s nothing you can do about it.
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
How to block rate-limited traffic with Varnish
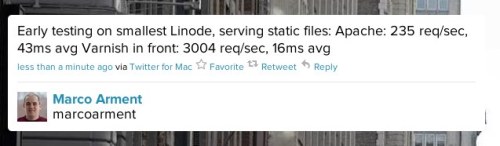
Varnish is brilliant. For those who don’t know it is a reverse proxy cache / HTTP accelerator which serves cached content quickly. Really really quickly. But don’t just take my word for it:
At Abelson Info we have started work on a public API product, and one of our concerns has been how to implement effective and scalable rate-limiting.
We already use Varnish to serve significant web traffic on behalf of Betfair so it seems a good fit to use as a front end cache for any public API we produce. So if we can also get it to implement rate-limiting (to be precise - blocking rate limited traffic) that will be great.
What we want is for our API application servers to count requests from a client (by IP address or API key) and when a rate-limit is exceeded, serve a header that indicates this, which Varnish can cache, and then block all subsequent requests (to any URL of the API) from that client until the block response expires; this means the application server controls the business logic that implements the rate limit, but Varnish deals with the rate-limited load.
This will be especially useful in the case of a denial of service attack, or what I like to call an “inadvertent denial of service attack” - when an innocent (but slightly incompetent) client writes a script that hammers your service with requests because they forgot to put a sleep in a loop (or similar). We have encountered these before with our non-public APIs, so opening up our APIs to everyone only makes the possibility of these more likely.
Here is my first attempt at a Varnish VCL (config file) that implements this:
# set back end as normal
backend default {
.host = "127.0.0.1";
.port = "81";
}
sub vcl_hash {
# uncomment next line to rate limit based on IP address
# set req.hash += client.ip;
# uncomment next line to rate limit based on query parameter ('key' in this case)
# set req.hash += regsub(regsub(req.url, ".+(\?|\&)key=", ""), "\&.*" ,"");
return(hash);
}
sub vcl_fetch {
# cache 400s (rate limited) responses
if (beresp.status == 400) {
set beresp.cacheable = true;
} else {
set beresp.ttl = 0s;
}
return(deliver);
}What this is doing is hashing every request from the client to look like the same request, and only caching the 400 (rate-limited) responses. TTL (time to live) is set in the cache-control header from the application server, so it is fully in control of implementing the rate-limit, and when a rate-limit should expire.
Aside: I chose 400 to represent a rate-limited response as that is what Twitter uses, and feels the most appropriate response code. You can of course any response you like (within reason)
There are two flaws to be addressed with this.
- If you are blocking based on an URL parameter, it will not help in the case where a user is deliberately launching a DOS attack, as all they need to do is change the key for each request. However if you are under a deliberate DOS attack, you probably have bigger problems anyway.
- This uses Varnish only as a rate-limited traffic blocker - the hashing function does not allow for any other sort of caching.
Initially my solution to problem (B) was to implement a second Varnish instance as the default back end, which would then implement ‘normal’ caching. But a bit of experimentation and tweaking brought me to this:
# set back end as normal
backend default {
.host = "127.0.0.1";
.port = "81";
}
sub vcl_hash {
if (req.http.X-rate-ok != "1") {
# uncomment next line to rate limit based on IP address
# set req.hash += client.ip;
# uncomment next line to rate limit based on query parameter ('key' in this case)
# set req.hash += regsub(regsub(req.url, ".+(\?|\&)key=", ""), "\&.*" ,"");
} else {
### these 2 entries are the default ones used for vcl.
set req.hash += req.url;
set req.hash += req.http.host;
}
return(hash);
}
sub vcl_fetch {
if (req.http.X-rate-ok != "1") {
# first pass - only cache 400s (rate limited) responses
if (beresp.status == 400) {
set beresp.cacheable = true;
return(deliver);
} else {
# not a rate limited response, so restart using normal hash function
set req.http.X-rate-ok = "1";
restart;
}
}
# non-rate limited fetch
return(deliver);
}
Here Varnish does an initial pass to see if there is a cached rate limited response, and if not it sets a flag (req.http.X-rate-ok) and restarts the request, which uses the default (or your custom) hashing function.
While we have not battle-tested this configuration yet, under test it seems to implement the exact functionality we want, and we look forward to using it on our live public platform.
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
The Stack Exchange Rep Recalc Ripoff
You will see from this page I am a moderately active member of the Stack Overflow community, and I have slowly been climbing towards 10,000 reputation (yes I know reputation, doesn’t really matter, that it’s just a gaming mechanism, but I like playing games, and 10,000 is a significant threshold as you get extra user privileges at that point)
So I was pleased to find a question of mine I had posted in early 2009 had been submitted to Hacker News, and was near the top of the front page. This would mean lots of views, upvotes, and therefore a climb in rep to near to my five figure goal.
Due to the traffic, the question obviously attracted the attention of the Stack Overflow mods, as they deemed it should be moved to programmers.stackexchange.com and migrated it there. (Which I don’t disagree with - Programmers.SO did not exist when I created the question)
Cut to a few days later, and overnight I seem to have lost over 500 rep points. This was due to one of SO’s periodic rep recalcs. The explanation for this must be that as my question was no longer on SO, when recalculating my rep any votes it had received on SO would have been ignored.
This seems slightly unfair, as for over 2 years it had validly been receiving votes, and only got migrated because of the attention of the Hacker News community thinking it was worth of linking to and discussing.
But to add insult to injury, the rep recalc on SO was not accompanied by a rep recalc on Programmers.SO so the rep I lost from SO I did not gain there. It completely disappeared! Hence the ‘rip-off.’
I hereby refuse to participate any further in the StackExchange community until they return my stolen rep to me!
Actually I don’t really care about my rep, I think the Stack Exchange network is fantastic and doing a great job, I just found this situation amusing. I bet some people really do care about rep though.
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
Three Mobile, purveyors of pron?
I have a mobile from Three, and last week while on the train, I tried to follow a link to Richard Herring’s blog from his Twitter stream.
This is what it started loading:
Now Richard Herring on occasion is known to use bawdy and risque humour, but it is all just text, and I wouldn’t say in the NSFW category.
Obviously his site is on some content blacklist, used by some software Three have bought (or written) to stop minors accessing undesirable content? That’s the reason isn’t it, protecting children? Lets see what the rest of the page looked like:
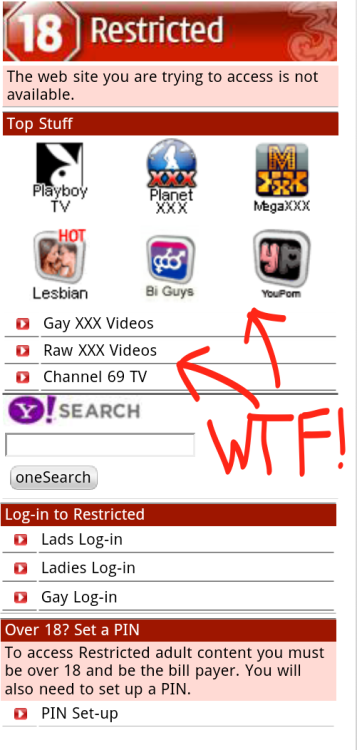
So on a page, to protect children it is advertising…well you can see can’t you?
Lets reiterate. This is the page you get if you have not confirmed you are 18. i.e.possibly a child.
So, maybe it is not for protecting children. Then what the hell is it for?
Oh, I see: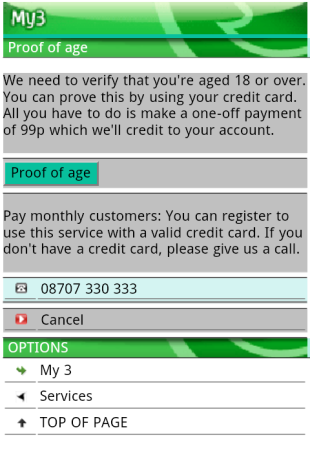
You want 99p from me. Is that a business model?
Or could it possibly be so you have my CC details, and assent for using ‘adult services’ so you can spam me with pron from now on?
Even worse, this thread: http://www.ww.3g.co.uk/3GForum/showthread.php?s=a7e8dff1dd04a17b9b674a23e004fef0&t=99413 seems to indicate that even if you do pay 99p to prove you are an adult, you still cannot access the content you want (like the Richard Herring’s blog), it just gives you access to Three’s paid for adult services.
It is at best pretty tawdry, and at worst, a blatant attempt to extract revenue from customers under the guise of protecting minors.
But the worst part is that they are blocking sites that are not pornographic, and dare I say, under 18s might want to legitimately use.
I notice b3ta.com, popbitch.com and holymoly.com are also blocked. But betting sites are not.
Edit (8th April 2011): Interestingly, while revisiting this blog post today, it appears Three have completely removed their content filter (for me anyway). I wonder if this is temporary or permanent.
Edit 2: Ah - an explanation: http://blog.three.co.uk/2011/03/18/easier-access-to-the-internet-on-your-mobile/
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
Geosay.com crawlable - success!
In my previous blog I wrote about how we had enabled ajax crawling of geosay.com.
Now after less than a month of spidering (and much tweaking to how the spidering functionality works) we have over 50 pages of results in Google.

This appears to have been achieved off just a small handful of links seeded around the Internet (this blog, a few tweets, and a handful of other places). This has resulted in our Google indexed pages being clustered around a few small areas: Paris, Hamburg and London.
However, that is not what I consider the major success (as the title states) of this exercise.
The success is this: Google Webmaster Tools tells me we had one visit from a search for “anamas in gänsemarkt”. At this moment in time the first result for this is a geosay.com page: http://geosay.com/#!map/lat=53.556667/lon=9.988889/z=16/t=2/f=1/w=1/g=1/
Big success huh? No.
The success is on that page, it actually shows you where a fruit shop called “Anamas Fruits” is in The Gänsemarkt. So a user has actually used geosay to find something they are looking for.
My work here is done.
Edit: While I’m at it here are a few more links to interesting places in geosay:
Princes Street, Edinburgh: http://bit.ly/epI8tT
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
Geosay.com is now crawlable
Although the front end has not changed much in the last few weeks, some effort has gone in on the back end to make geosay.com crawlable by web spiders.
As geosay relies heavily on JSONP requests from third parties, making the site spiderable has been non-trivial. Progressive enhancement would just not work for geosay.
A few months back we enabled ajax urls (using #!); this meant it was possible to share links and refresh the page and return to the same content.
The latest release now makes use of these as described in Google’s Making Ajax Applications Crawlable.
Part of the reason for this post in an excuse to put in a few links to geosay to see if Google will choose to spider them.
This is The Houses of Parliament, London on geosay (map view).
This is Times Square, New York (map view).
This is The Eiffel Tower (streetview)
And just to have something a bit more obscure for Google to spider, here’s a restaurant I like called ‘Da Lucio’.
Twitter search seems to be having issues at the moment. There is an existing ticket for our issue: http://code.google.com/p/twitter-api/issues/detail?id=1996 . Comment 11 is interesting. Will look forward to the resolution.
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
A quick update
I have been lax in keeping my blog up to date recently; I have an unpublished blog post about Virgin Media, which to be honest, I don’t really have the belligerence to publish yet (although if they annoy me any further I will. Lets say it is still not fully resolved.)
I also have an unwritten blog post about 3 mobile. But in my final research I realised I actually couldn’t back up the main thrust of the post, so that will remain unpublished until I get new evidence that justifies my argument.
Finally, I have started a github account and have posted a jQuery plugin there that wraps the functionality in my post Detecting a Brower’s Language in Javascript.
So far I really like github. I think it is probably instrumental in the proliferation of open source activity recently.
Need help with stuff like this?
I am currently available for hire through Reason Factory
I am currently available for hire through Reason Factory
